
VPN/Non-VPN Network Application Traffic Dataset (VNAT)
The dataset consists of 36.1 GB, 33,711 connections and approximately 272 hours of packet capture from five traffic categories, as shown in the table below:
|
Traffic Category |
Applications |
Filename Keywords |
|
Streaming |
Vimeo, Netflix, Youtube |
vimeo, netflix, youtube |
|
VoIP |
Zoiper |
Voip |
|
Chat |
Skype |
skype-chat |
|
Command & Control (C2) |
SSH, RDP |
ssh, rdp |
|
File Transfer |
SFTP, RSYNC, SCP |
sftp, rsync, scp |
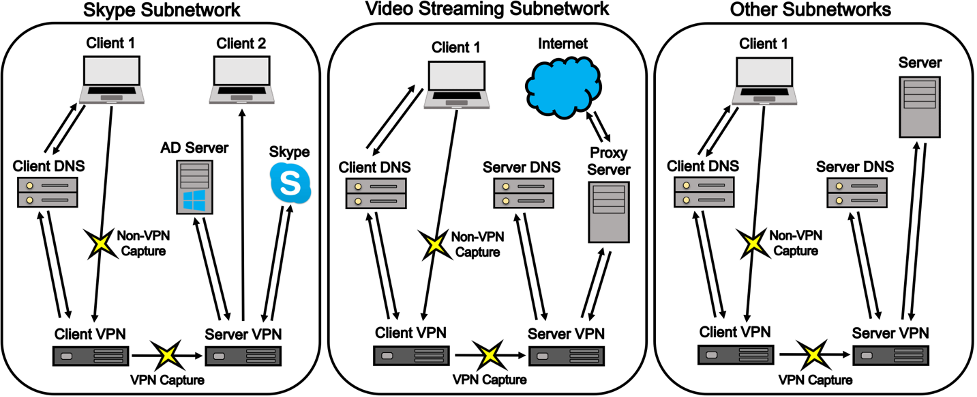
To produce the dataset, virtual subnetworks for each traffic category were created. Each subnetwork contains a client, a client DNS server, a VPN client, and a VPN server. The Skype subnetwork contains an additional client to allow for bidirectional chat. The video streaming and web browsing subnetworks were connected to the Internet to enable access to Firefox, Chrome, YouTube, Netflix, and Vimeo. VPN traffic was captured between the VPN client and the VPN server. Separately, non-VPN traffic is captured between the VPN client and the application layer.
Netflix, YouTube, Zoiper, and Vimeo network traffic were generated manually. However, the File Transfer network traffic was generated with the assistance of randomized scripts. The Chat category was created by playing back chat messages available on https://github.com/freeCodeCamp/gitter-history. For the C2 category, the RDP traffic was manually generated, whereas the ssh traffic was created with randomized scripts that executed shell commands. All traffic was captured using tcpdump and outputted in the libpcap compatible PCAP format.
Download Instructions
The PCAP dataset is provided as a single .zip archive which contains all the raw PCAP files. We also provide two .h5 files that can be directly loaded via the Python Pandas package. “VNAT_Dataframe_release_<#>.h5” contains the connection, packet timestamps, packet sizes, and packet directions from the PCAPs already extracted into a Pandas DataFrame. “VNAT_Feature_Dataframe_release_<#>.h5” contains machine learning feature data extracted using Wavelet-based and TLS-based methods described in the paper linked at the bottom of this page. Users can infer labels from the file names provided (VPN, non-VPN, apps, categories, etc.). Simply download the .zip file and extract it to begin using the PCAP data or download one of the .h5 files and extract the data using the following python code (ensure you have the pip packages “pytables” and “pandas” installed):
import pandas as pd df = pd.read_hdf(“VNAT_Dataframe_release_<#>.h5”)
This was tested on python 3.8 using pandas v1.4.3 and likely works for python >= 3.8 and pandas >= 1.4.
The data was captured using TCP dump on an isolated subnetwork where only network traffic from the desired application was present. Since all applications captured encrypt the packet payloads, no obfuscation of the payload is required. Since the packets were captured on an isolated subnet created for only this purpose, no obfuscation of packet header data was required. After the PCAP data was captured, files were labeled according to the application run during the capture using the following format:
|
Capture Type |
File Naming Format |
|
VPN |
vpn_<filename keyword>_capture<#>.pcap |
|
NON-VPN |
nonvpn_<filename keyword>_capture<#>.pcap |
More information about the dataset can be found in our related publication, available at https://ieeexplore.ieee.org/abstract/document/10044382.