
Exploiting Risk-taking in Group Operations
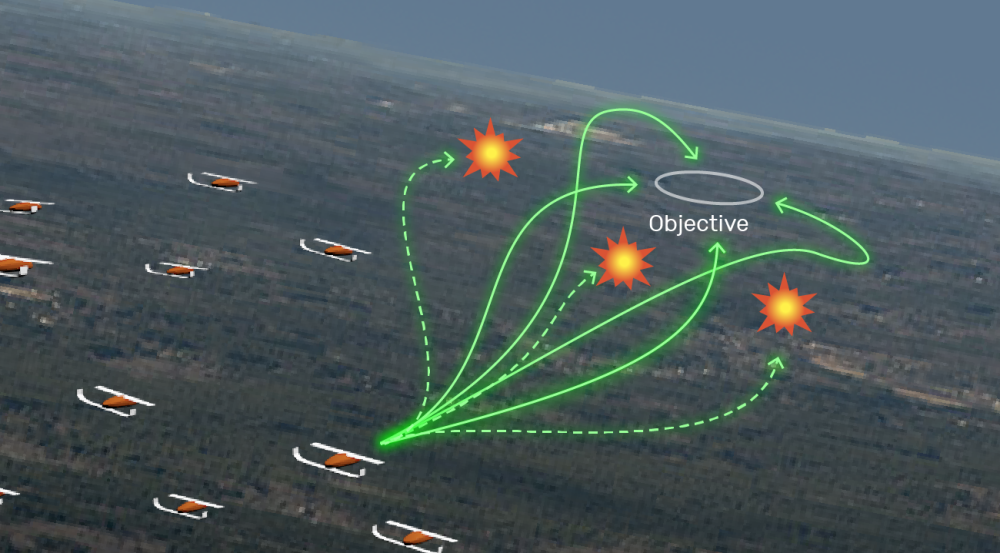
Autonomous systems that work together are well suited for tasks that pose risks to human operators. However, developing optimal coordination strategies for such multi-agent systems grows more complex with the number of agents involved. The recently developed field of multi-agent deep reinforcement learning (MARL) may offer the best approach for solving such coordination issues. Driving MARL research is the multi-agent credit assignment problem of determining which agent’s actions are most responsible for the overall performance of the team.
In the Exploiting Risk-taking in Group Operations (ERGO) project, we are developing algorithms that train teams of autonomous systems to use risk taking—i.e., taking actions that may lead to the degradation or destruction of a single agent — in order to determine how a team’s performance changes if and when an agent is eliminated. An example of this type of reasoning, called counterfactual reasoning, is the post-game review of a soccer team’s performance. Upon review, the team hypothesizes how the score would have changed had Player X been taken out of the game at a given time. If this hypothetical score goes down, then Player X made important contributions; if the score goes up, then Player X was actually hurting the team. Thus, we have assigned a value to the player’s actions. Using counterfactual reasoning, ERGO’s algorithms have been shown to learn collaboration strategies much faster than other state-of-the-art MARL techniques.
Moving forward, we will focus on developing a scalable computing architecture that allows us to simulate realistic serious games and decision problems that are relevant to Department of War missions. These simulations will enable ERGO’s MARL algorithms to reveal strategies for well-studied problems, such as many-on-many air-to-air engagements, as well as strategies for future and emerging conflicts.
Related
Events
RAAINS - Recent Advances in AI for National Security 2027
News


Enabling privacy-preserving AI training on everyday devices
